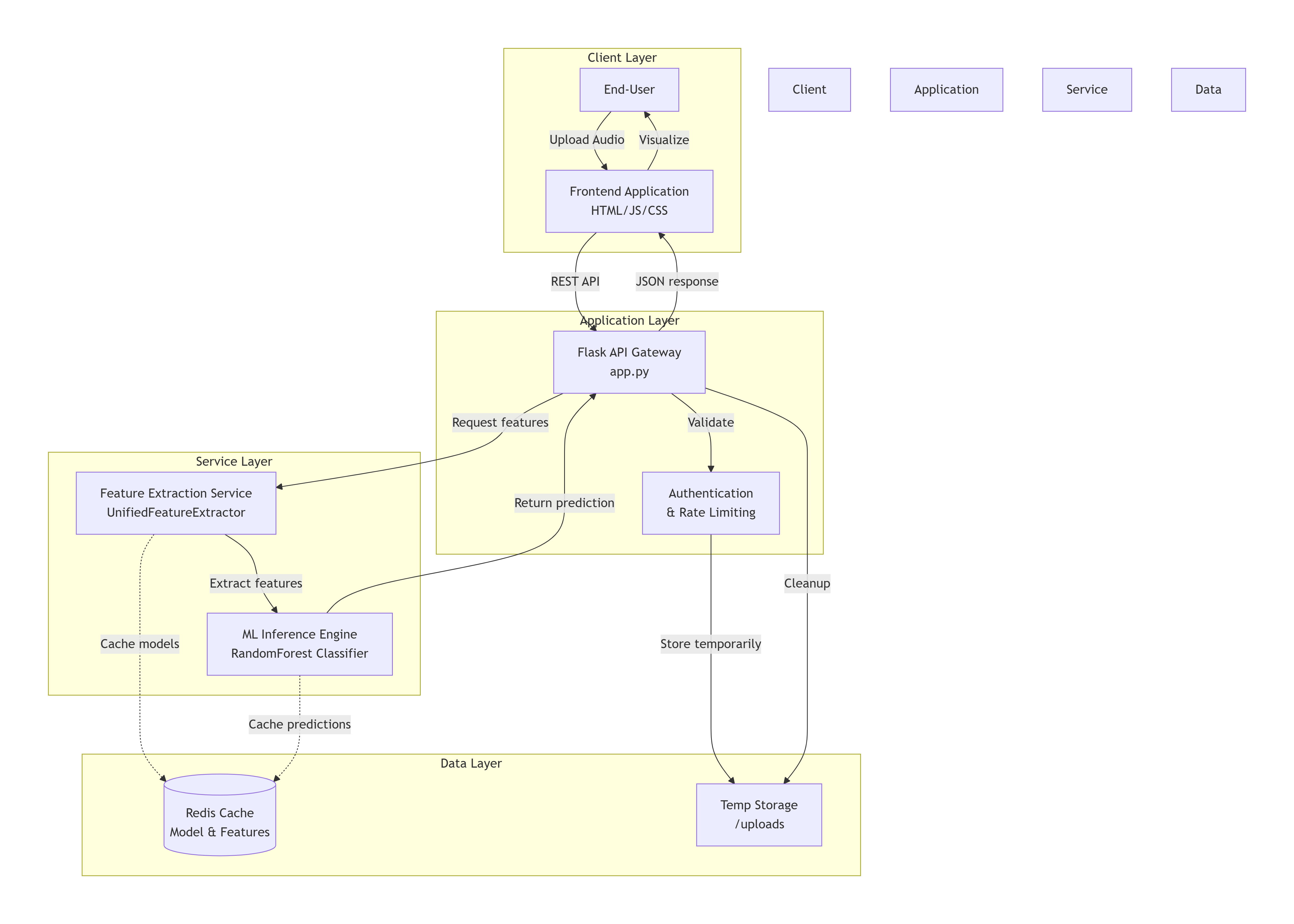
The Threat of Voice Cloning
As Generative AI rapidly advances, malicious actors can now clone voices with terrifying accuracy using only a few seconds of source audio.
-
Social Engineering: Voice-phishing (vishing) attacks targeting financial institutions and vulnerable individuals.
-
Misinformation: Generating fake statements from public figures to manipulate public opinion.
-
Authentication Bypass: Defeating voice-biometric security systems.